Vor einiger Zeit habe ich über die gravierenden Mängel des Online-Petitions-Systems vom Deutschen Bundestag berichtet. In der Zwischenzeit wurden zwar einige kleine kosmetische Reparaturen vorgenommen, das Grund-Problem der gammeligen Software besteht aber weiterhin. Unter der „hohen“ Last von rund 16000 Unterzeichnern einer Petition ist der Spaß jetzt zusammengebrochen. (Updates unten: Probleme halten an)
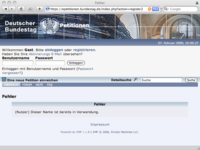
Seit einigen Tagen ist die Petition zum Bedingungslosen Grundeinkommen sehr beliebt und hat viele Unterzeichner erhalten, der Zähler steht bei über 16000. Nun zeigen sich die ganzen Mängel des unzureichenden Systems, wie einige Leser berichteten und ich verifizieren konnte: Durch einen Fehler ist es nicht mehr möglich, dass sich neue Nutzer registrieren und ohne Registrierung ist es auch nicht möglich Petitionen zu unterzeichnen. Dies äußert sich darin, dass nur eine Fehlermeldung erscheint:
Fehler
(Nutzer) Dieser Name ist bereits in Verwendung.
Dies dürfte an einem Datenbank-Fehler liegen und eine Folge der Wahl der technischen Basis sein – die den grundlegenden Anforderungen des Bundesamts für Sicherheit in der Informationstechnik (BSI) widerspricht. Ein paar technische Hintergründe dazu weiter unten.
Das ist aber nicht alles: die PHP/MySQL-Software ist auch an anderer Stelle bei rund 16000 Unterzeichnern einer Petition überfordert, die Anzeige der Unterzeichner wurde daher generell auf 100 begrenzt. Das sieht wie eine schnell eingebaute Notmaßnahme aus, um die Last des Systems zu begrenzen. Denn laut diversen Berichten wurde das Petitionssystem zuvor immer langsamer. Auch das ist ein Zeichen für schlechten Code.
Die Beschwerden im Forum häufen sich, zumal die Zeichnungsfrist für die Grundeinkommens-Petition am 10. Februar abläuft. So fragt der Nutzer Thomas Köppel:
Tja, wie es aussieht ist das System auf dem die Petitionssoftware (Datenbank) aufgesetzt ist, an seine Grenzen gestoßen.
Es bedarf wohl einer besseren Infrastruktur, für das handling des großen Datenaufkommens, ich frage mich was passiert wenn über 1 Millionen Menschen gleichzeitig Zugriff auf das System nehmen.
Viele Grüße
T.K.
Eine Million gleichzeitiger Zugriffe würde zwar fast jedes System zum erliegen bringen; aber insgesamt bei einer Million Unterzeichnern (bzw. Datenbankeinträgen) hat ein anständiges Datenbanksystem keine Probleme. Schließlich sind Datenbanken dafür da, große Datenmengen effizient zu verwalten.
Und Nutzer16941 schreibt:
Das ist leider ein Armutszeugnis für unsere Demokratie (und damit für uns das Volk), wenn unsere Regierung davon ausgeht eine kleines(?) System reicht aus. Denn scheinbar hat es das ja seit Jahren.
Dazu ist anzumerken, dass die Anforderungen an das neue System u.a. waren, dass es im Peak 50000 Nutzer sowie Petitionen mit beliebig vielen Unterzeichnern aushalten muss. Hier zeigt sich wieder, dass das neue System wie beschrieben eben nicht den Anforderungen entspricht.
Denn all das erinnert an das alte Petitions-System, das noch vom schottischen Parlament erstellt wurde. Nun wollte man alles besser machen, aber es wurde nur ein tiefer Griff ins Klo in die Problemkiste: Eine Bundestagsverwaltung, die technische Angebote nicht lesen und verstehen kann (schließlich haben die dortigen Mitarbeiter normalerweise anderes zu tun) und sich daher auf die Behauptungen in den Angeboten verlassen muss, ein Ausschreibungsrecht, dass den günstigsten Anbieter verlangt und eine Firma, die alles mögliche behauptet aber nicht viel einhält – all das zusammen sind meines Erachtens die Hauptgründe für das Dilemma. Den Bundestag sehe ich dabei eher als Opfer.
Aus mehreren Quellen weiss ich, dass derzeit eine Studie zur Online-Petitions-Plattform für das Büro Technikfolgenabschätzung des Bundestages erstellt wird. Die Plattform wird vor Fertigstellung der Studie wohl kaum grundlegend überarbeitet werden – und es ist zu hoffen, dass sie danach komplett weggeworfen und ein ganz neues, sauberes System erstellt wird. Dem Petitionswesen wäre das zu wünschen.
Und woran liegen die Probleme aus technischer Sicht?
Das Problem, dass niemand mehr registriert werden kann, liegt vermutlich an einem Datenbank-Problem, das unter Last auftreten kann. Dazu muss man wissen, dass die Nutzer ihren Nutzernamen nicht frei wählen können, sondern einen Namen „Nutzer12345“ mit fortlaufender Nummer zugewiesen bekommen. Die Petitions-Software basiert auf dem „Simple Machines Forum“, das als Datenbank-Backend MySQL mit MyISAM-Tabellen verwendet – was keine Transaktionen und Datensicherheit unterstützt und bei mehreren gleichzeitigen Zugriffen ohne besondere Maßnahmen sehr langsam wird und schon mal den einen oder anderen Fehler erzeugt. Aber auch wenn Transaktionen unterstützt werden können können ähnliche Probleme auftreten, beispielsweise zwei gleichzeitige nicht synchronisierte Zugriffe (zum Beispiel durch das fehlende Sperren einzelner Datensätze) und der Zähler für die Erstellung der Nutzernamen ist durcheinander gekommen. Dies nennt man Race Condition (Wettlaufsituation), zwei oder mehr Zugriffe rennen quasi um die Wette und greifen gleichzeitig auf eine Ressource zu, die nur einmal vorhanden ist.
Dumm gelaufen – bei professioneller Software darf sowas nicht passieren. Darum verlangt das BSI ja auch entsprechende Mechanismen und eine ACID-Konforme Datenbank bzw. Software, die diese Funktionen auch nutzt. Aber der Dienstleister hat sich nicht daran gehalten. (mehr zur Petitions-Software ...)
Die langsamen Antwortzeiten bei vielen Unterzeichnern hängen möglicherweise auch (aber nicht nur) mit MySQL und MyISAM zusammen, ein übliches Szenario ist: die Queries (Datenbank-Abfragen) dauern bei vielen Unterzeichnern (also vielen Daten) länger, sperren aber schon beim Lesen die ganze Tabelle für Schreibzugriffe. Schreibzugriffe müssen warten und wenn diese dran sind, müssen die Lesezugriffe warten. So schaukelt sich das ganze unter Last bis zur Unbenutzbarkeit hoch und schon bei relativ niedrigen Nutzerzahlen kann alles zusammenbrechen. Eine andere Möglichkeit ist, dass durch mehrere gleichzeitige lang laufende Datenbankabfragen die Performance in den Keller geht, dadurch mehr Abfragen gestartet werden und irgendwann der Speicher voll ist.
Zudem wurden in letzter Zeit wieder diverse gravierende Sicherheitslücken im verwendeten Simple Machines Forum bekannt. Auch das sorgt nicht gerade für Vertrauen in die Petitions-Plattform. Ebensowenig wie gelöschte Forums-Einträge und gesperrte Diskussionen. Beispielsweise ein gut implementiertes Bewertungssystem könnte das Löschen von Einträgen nahezu unnötig machen.
Die Probleme der Software sind meines erachtens eine große Schande für die Firma araneaNET GmbH, die groß damit wirbt BSI-Zertifiziert zu sein, aber dann MySQL und auch noch Software ohne Transaktionen verwendet, was eben nicht den BSI-Anforderungen entspricht und einer der Gründe der schwerwiegenden Probleme sein dürfte. Auch eine simple Änderung von MyISAM zu InnoDb ändert an der grundsätzlichen Problematik des Simple Machine Forums nichts. Da sieht man mal wieder: solche Zertifikate sind oft nur Schall und Rauch und sagen nur aus, dass da jemand ein wenig Geld in Marketing und vielleicht theoretische Fortbildung steckt.
[Nachtrag, 16:17:]
Ein weiterer Forums-Beitrag von Roswitha61 deutet auf mehr Probleme hin:
Bei mir erscheint "nur eine Mitzeichnung erlaubt". Ich habe mich aber gerade erst registriert und folglich noch gar nicht unterzeichnet.
Was ist das?
Sollte dies echt sein, könnte es sein, dass es noch weitere und massive Datenbank-Probleme gibt.
Die eingangs geschilderte Fehlermeldung erschien bei meinen Tests nun nicht mehr, aber es kommt bei einer Registrierung auch keine Bestätigungsseite und die Bestätigungs-E-Mail habe ich auch nicht erhalten.
[Nachtrag, 8. Februar, 12:15:]
In der Zwischenzeit scheint die Registrierung tatsächlich wieder zu funktionieren. Ich hatte es gestern Nachmittag und Abend mehrfach probiert, wurde aber nach Absenden des Registrierungsformulars ohne weiteren Kommentar oder Fehlermeldung auf die Startseite umgeleitet. Auch eine Bestätigungs-Mail ist nie eingetroffen. Dies lag daran, dass ich vergessen hatte den „Ich bin einverstanden“ auszuwählen. Es wird keine entsprechende Fehlermeldung ausgegeben, sondern der Nutzer wird dann nur auf die Startseite umgeleitet – auch das ist nicht sehr benutzerfreundlich. Einträge im Forum zeigen, dass dies nicht nur mir so passiert ist, die „Ich bin einverstanden“ Checkbox ist nicht sonderlich gut positioniert. Und es häufen sich auch die allgemeinen Beschwerden über die schlechte Benutzerführung.
Zudem konnte man bisher eine Unterzeichnung wiederrufen; da nur noch 100 Unterzeichner angezeigt werden und darunter nicht die neusten sind, findet man sich selbst aber nicht mehr in der Unterzeichnerliste und kann damit eine Unterzeichnung auch nicht rückgängig machen ...
Das obige Problem, dass das Petitionssystem behauptet der Nutzer hätte schon unterzeichnet obwohl dieser da anderer Ansicht ist, tritt auch bei weiteren Nutzern auf. Ob diese nur zweimal auf den Unterzeichnen-Button geklickt haben oder es tatsächlich ein Fehler ist kann ich aber nicht sagen. Ordentliche Software würde dies aber entsprechend abfangen ...
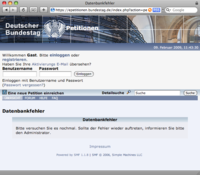
[Nachtrag 9. Februar, 15:32]
Heute reagiert die Petitions-Webseite wieder extrem langsam, manchmal treten auch Datenbank-Fehler auf (siehe Screenshot rechts). Der Zugriff auf eine Seite kann schon mal mehrere Minuten dauern, ganz abbrechen oder mit einer solchen Fehlermeldung enden.
Selbst das Laden eines statischen Bildes dauert schon mal mehrere Sekunden bis Minuten oder wird ganz abgebrochen. Dies deutet auf tiefergehende Probleme hin (Überlastung aufgrund sich gegenseitig blockierender Datenbankzugriffe und dadurch zu vieler Apache-Prozesse) – was ich gleich mal zum Anlass nehme, um in einem eigenen Artikel Tipps zum Umgehen dieser Probleme zu schreiben.
Bereits heute Vormittag wurde aufgrund der Probleme die Zeichnungsfrist für die Petition „Bedingungsloses Grundeinkommen“ um eine Woche verlängert. Das Forum wird aber morgen geschlossen – wahrscheinlich wird es den Moderatoren einfach zu viel Arbeit. Tja, mit einem selbstregulierenden System mittels eines flexiblen Bewertungssystems hätten sie kaum Arbeit, da die Nutzer die Trolle gleich selbst entsorgen könnten.
[Nachtrag 10. Februar, 16:10]
Die Probleme mit der Performance bestehen weiterhin: Lange Wartezeiten, teilweise kommt auch der gleiche Datenbankfehler wie im Screenshot eins weiter oben, und manchmal schlägt auch der Timeout vom Browser zu. Die große Frage ist, ob überhaupt Maßnahmen ergriffen werden, die Probleme zu beseitigen.
[11. Februar, 0:25]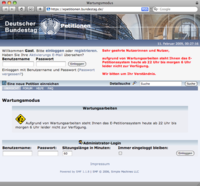
Nun ist alles im „Wartungsmodus“ und außer Betrieb. Vielleicht wird nun alles auf besser ausgestattete Hardware umgezogen. Nach dem Motto: Versuchen wir mal unzureichende Software mit dickerer Hardware zu erschlagen.
Unteressanterweise änderte sich die Darstellung der Fehlermeldung innerhalb weniger Minuten, anfangs war der rote Text oben noch schwarz und nicht fett ...
[12. Februar]
Tatsächlich, die Last-Probleme scheinen zumindest vorerst behoben zu sein.
[17. Februar]
Der Server ist wieder zusammengebrochen, Datenbankfeher inklusive ...
[4. Mai]
Und bei der neuen Online-Petition gegen Internet-Sperren wird der Server wieder langsam ... Sehr langsam ...

Wie gerade jemand in den heise Foren schreibt, und ich verifizieren konnte,scheint auch die Webseite von araneaNet aktuell nicht erreichbar zu sein. Heute Morgen ging die noch. ;-)
Gruß ZEITungsleser
Tja, da kommt alles zusammen. Oder sie schämen sich so, dass sie ihre eigene Webseite abgeschaltet haben ;-)
Hier der entsprechende Eintrag im Heise-Forum.
Was geschieht in einem Fall, wo z.B. erst ab 100.000 Unterschriften ein Thema von der Bundesregierung ernst genommen wird und die Datenbank sich aber bereits bei 16.000 verschluckt?
Glaubt die Regierung dann vielleicht, dass die Petition nur als geringfügig einzuschätzen ist.
Zufall oder Intention?
Aktuell scheint das System halbwegs geflickt worden zu sein. Neuanmeldungen und Mitzeichnen sind laut Aussagen aus dem Forum wieder möglich.
Ungeklärt ist weiterhin die Herkunft der angezeigten Liste von 100 Mitzeichner. Erwarten würde man ja, dass die letzten Mitzeichner angezeigt werden. Welches aber nicht sein kann, da der Counter der Unterstützer aktuell wieder nach oben geht, die Liste sich aber nicht verändert. Bliebe die Möglichkeit einer periodisch generierten Liste, um die Datenbank noch mehr zu entlasten. Wobei die Seite dann aber wesentlich schneller ausgeliefert werden sollte. Aber vielleicht sind es auch nur die ersten 100 des aktuellen Tages, anstatt der letzten.
Interessanter Weise ist jetzt die Webseite des "Herstellers" auch wieder erreichbar. Ich will einmal nicht hoffen, dass dies zu bedeuten hat, dass auch nur Teile deren Hardware irgendetwas mit den Datenbanken des Petitionssystems zu tun haben.
Ich bin gespannt, wann und was als Erklärung in den nächsten Tagen angeboten wird.
In diesem Sinne, erst einmal noch ein schönes Wochenende :-)
Zwar habe ich auch gelesen, dass das Anmelden wieder möglich sein soll.
Bei einem Versuch heute Mittag kam auch keine Fehlermeldung – aber auch keine Bestätigungsseite, sondern nur eine Umleitung auf die Startseite. Bestätigungsmails habe ich bis jetzt keine erhalten.
Wurde die Frist denn jetzt wenigstens verlängert?
Hoffentlich kriegen die schnell ein vernünftiges System hin, denn es ist zu erwarten, dass dieser ersten Petition eine weitere folgt, in einer konzertierten Aktion aller Verbände und Sympathisanten...
Das ist einfach zu lächerlich das System.
Ich meine wenn die nur ein bisschen Ahnung von Cluster Techniken hätten...
MySQL kann locker mehr Daten packen.
Wichtig ist, dass die Datenbank auf einem anderen Server ist als der Webserver oder gleich im Cluster steht mit Loadbalancer davor.
Es ist echt eine Schande das es bei 16000 Nutzern am brechen ist.
Ich kenne so viele Foren die deutschlich mehr haben.
Ein Bottleneck mag auch die SSL Verschlüsselung sein. Deswegen denk ich das beide Systeme an der Grenze sind.
Meine Meinung: Cluster her
Salut, Martin,
Was auch immer MySQL damit zu tun hat. Ich glaube, hier liegen zwar durchaus einige Hunde begraben, aber sicher nicht dieser.
Ich habe eher das Gefühl, dass du ein Produkt kennst (kennen gelernt hast?) welches dich fasziniert, und das du nun an den Mann bringen willst...
Ich denke aber, dass eine Regierung, die nicht gerade Basel-Stadt ist, zu wenig Ressourcen vorhält um dynamisch reagieren zu können wenn eine Petition oder was auch immer für ein Dienst sich plötzlich unerwarteter Benutzerfrequenzen erfreut. Ich weiss also nicht, ob das Problem überhaupt lösbar wäre, auf organisatorischer Ebene, falls tatsächlich eine halbe oder ganze Million Benutzer vorbei schaut.
Man kann es natürlich auch wieder dem Terrorismus zuschreiben. Oder man hört auf die Firmen Sun und SyGroup, die beide auf PostgreSQL-Cluster setzen. ;-)
Tonnerre
Salut, ZEITungsleser,
Vielleicht läuft die Webseite des Herstellers ja auf demselben Server? ;-)
(Nein, das abweichende Subnet ist kein Indiz.)
Tonnerre
Martin: Das hat weder etwas mit Cluster zu tun noch ob die Datenbank auf einer eigenen Maschine läuft oder nicht. Zudem ist es ja nicht bekannt, wie MySQL dort genau eingerichtet ist.
Selbstverständlich kann man MySQL oder eine beliebige andere Datenbank auch auf der gleichen Maschine wie den Webserver betreiben und das ganze ohne Cluster, ohne dass man Angst haben muss, dass die Datenbank kaputt geht. Zumal das kritische Problem bei der Petitions-Webseite ja der Ausfall ist, der vermutlich auf eine Dateninkonsistenz in der Datenbank zurückuzführen ist. Bei MySQL und MyISAM ist es in vielen Fällen mit einigem Aufwand verbunden und in vielen anderen unmöglich, eine 100%ige Datenkonsistenz zu gewährleisten. MyISAM kann keine Transaktionen und ohne Transaktionen kann man nicht sicher sein, dass mehrere Daten-Änderungen konsistent in der Datenbank abgelegt werden.
Ein Cluster macht es prinzipiell sogar noch schwerer, Datenkonsistenz zu gewährleisten, da die Synchronisierung über mehrere Maschinen laufen muss. Die Daten des MySQL-Cluster können zudem in 5.0 nur im RAM abgelegt werden, was in diesem Falle hier natürlich nicht wirklich sinnvoll ist. 5.1 will man aus den bekannten Gründen nun nicht wirklich einsetzen ...
Zur Performance-Steigerung gibt es bessere Methoden als MySQL und den MySQL-Cluster. Vor allem sind 16000 Unterzeichner nun nicht so viel, dass ein normal ausgestattetes System zusammenbrechen sollte. Das ist ein Zeichen für schlechten Code (siehe auch meinen Vortrag zu Performance-Optimierung).
Als Beispiel: Auf dieser Maschine, auf der auch das Blog hier läuft, läuft ein MySQL mit einer Datenbank mit einer Größe von über 9 GB, eine Tabelle hat über 25 Millionen Zeilen. Auf der gleichen Maschine (aber in einem anderen Jail) wie Webserver und Co. Und mit deutlich mehr Zugriffen als bei der Petitions-Webseite ...
Dennoch nehme ich bei neuen Projekten kein MySQL mehr: PostgreSQL kann viel mehr, ist sicherer, kann Datenkonsistenz gewährleisten, hat nicht die vielen MySQL-Gotchas, es gibt keine Lizenzprobleme und zu guter letzt: Postgres ist in den meisten Fällen schneller. Aber das alles ist wieder ein ganz anderes Thema.
Hi Tonnerre
Ja, ich habe deinen Smiley gesehen. ;-)
Aber wenn die Webseite des Systems wirklich auf dem Server des Herstellers beheimatet wäre, hätte ich wohl noch ein viel größeres Problem, als "nur" ein technisches.
Gruß ZEITungsleser
Haue ha
Gerade mal wieder auf die Seite geschaut. Steht doch justamente in dicken Lettern "Datenbankfehler" da. Wer hätte das gedacht.
Gruß ZEITungsleser
Welche Distribution unterstützt eigentlich noch Openssl 0.9.8a (aus 2005) mit Security Fixes? Okay, in den Response Headern kann man viel behaupten. Aber so wie der aufgebaut ist, sieht der mir nicht aus, als hätte da jemand selbst Hand angelegt.
Ja, schon den ganzen Tag sind wieder massive Probleme da (siehe Update oben). Manchmal kommt auch Minutenlang nichts, bis die Browser das abbrechen.
Ich habe heute mehrfach versucht auf die Seite zuzugreifen. Entweder hat es ewig gedauert oder Fehler. Für eine Regierung ist dsa echt peinlich soetwas.
Salut, Andreas,
Ja, DSA ist peinlich, aber was hat das hiermit zu tun? ;-)
Tonnerre
Salut, ZEITungsleser,
Ich glaube, du brauchst mal einen Crashkurs in Distributions-Releaseengineering. Melde dich gerne bei einer Distribution deiner Wahl und schaue rein wie die das machen, und warum die eine oder andere Version etwas niedriger ist als die aktuellste, aber trotzdem frei von bekannten Sicherheitslücken und ähnlichen Problemen.
Tonnerre
Wobei ich jetzt den Korrekturonkel spielen muss: der Bundestag ist das Parlament, nicht die Regierung. Wir haben ja noch die Gewaltenteilung ...
Hochperformante Systeme baut man nicht mit Apache, PHP und MySQL. Punkt.
Das war der einfache Teil. Jetzt der Schwierige: Wie baut man dann eine performante Site? dazu muss man erst einmal wissen, was man NICHT tun sollte: Plattenzugriffe.
Ein Zugriff auf die Platte kostet ca. 7-10 Millisekunden, mit einem ORM (Object-relational mapper) auch gerne mal 200 Millisekunden.
Ein RAM-Zugriff kostet hingegen ca. 10 Nanosekunden, d.h. ist günstigstenfalls um den Faktor 20000 schneller,
was bedeutet, dass das Gesamtsystem bei gleicher Last aus einem Server statt einem kompletten Rechenzentrum bestehen kann.
Der nächste Flaschenhals sind die Einzelprozesse des Apache, die immer nur einen Request abhandeln können und dann erst den nächsten Request annehmen. Wenn jetzt langsame Clients dazukommen, blockiert ein einzelner Client schon mal einen der (sinnvoll max. 256) Prozesse für mehrere Sekunden. Passiert das mit 256 langsamen Clients, ist der Server de facto tot. Nachzuvollziehen ganz einfach mit einem kleinen Script, das 500 parallele Requests zu einem Server aufbaut und dann einfach 30 Sekunden nichts tut - peng, kaputt. Daher werden wirklich performante Server als Single thread mit einem select() gebaut. Damit kann eine einzelne CPU zigtausende parallele Abfragen bearbeiten und kommt nicht aus dem Tritt.
Und was ist mit Transaktionen, fragt der geneigte Leser?
Wirklich große Systeme benutzen keine. Zu teuer, nicht skalierbar, nicht zu synchronisieren. Ebay zum Beispiel - Hunderttausende von parallelen Anfragen/Käufen etc, aber keine einzige Transaktion. Die meisten Datenbewegungen werden sogar asynchron weggeschrieben, genau wie bei einem Journaling Filesystem - wenn der Server stirbt, muss man beim Wiederanfahren nur das Journal nachspielen und alles ist auf dem Stand wie vorher.
Der letzte Punkt: Cachen statt rechnen - Systeme mit memcached oder memcachedb liefern gerne auf einer einzelnen CPU 7000 Seiten/Sekunde aus.
Für die Liste der Untzerzeichner heisst das z.B. dass man nicht bei jeder Abfrage die Liste generieren muss, sondern nur dann, wenn ein neuer Unterzeichner dazu gekommen ist - voila, 17000 Generierungen in 30 Tagen statt 10 pro Sekunde. Das schafft Performance.
Just my 0.02€
Tach zusammen
Habe mich bereits vor fast 2 Wochen registriert und auch meine Stimme vergeben.
Schau ich heute in mein Nutzer Profil finde ich folgendes
Gesamte Online Zeit: 24 Minuten
Beiträge insgesamt: 0 Beiträge
Beiträge gestartet: 0 Themen
Erstellte Umfragen: 0 Umfragen
Abgegebene Stimmen: 0 Stimmen
Wollte das nur mal anmerken. Habe auch schon zwei weitere Dokumentationen dazu im Forum der Petition gefunden. Auf der ursprünglichen großen Liste war ich jedoch zu finden.
Hallo Olaf,
im Wesentlichen gebe ich Dir Recht, allerdings muss man das nicht in jedem Falle nicht ganz so eng sehen und auch nicht so weit gehen. Es ist alles immer eine Frage von Aufwand vs. Nutzen. Wir reden hier ja nicht über eine Anwendung mit mehreren Millionen Nutzern am Tag oder in der Stunde.
Festplattenzugriffe sind sehr oft der Flaschenhals, ja; aber selbst bei 30 oder 50 Millisekunden ist das an sich noch nicht tragisch, wenn es denn dabei bleibt. Und schnelle Server-Platten bringen auch einiges, wenn das RAM nicht ausreicht.
Bezüglich Apache-Flaschenhals: Die Frage ist ja, wieviele tatsächlich gleichzeitige Zugriffe man hat. Ein Apache kommt gut mit ein paar hundert gleichzeitig offenen Verbindungen zurecht, und das reicht sehr weit! Natürlich sollte man eine Reverse-Proxy-Architektur aufbauen, damit die vielen (eventuell langsamen) Verbindungen von den leichtgewichtigen Frontends abgehandelt werden können und die Backends sich auf das schnelle Ausliefern der dynamischen Inhalte ans Frontend beschränken. Ansonsten kann es sehr schnell passieren, dass das RAM voll ist und wenn die Kiste erstmal zum Swapping komm, dannt schlägt das von Dir beschriebene Szenario zu ...
Das eBay-Beispiel ist zwar richtig, aber da spielen wir in ganz anderen Dimensionen und die eBay-Entwickler sorgen eben mit ensprechendem Aufwand dafür, dass alle Daten synchron sind. Normale Web-Sachen betrifft das weniger. Zumal ähnliche Verfahren wie das asynchrone Rausschreiben auch bei Transaktionsorientierten Datenbank-Servern genutzt werden (Postgres und das WAL zum Beispiel, das ist sehr fix).
Memcached ist eine tolle Sache, in vielen Fällen (zum Beispiel viele Zugriffe und kleine Daten) lohnt es sich aber auch die Daten selbst im RAM zu halten, zum Beispiel in einem Perl-Hash. Das ist nochmals sehr viel schneller. Das mache ich zum Beispiel beim Assoziations-Blaster, der auch auf diesem Server hier läuft und vermutlich deutlich mehr Zugriffe hat als der Petitions-Server ... ;-)
20000 Unterzeichner würde ich nicht auf einer Seite anzeigen (auch wenn ich ein Freund von langen listen bin und 10er Schritte nicht komfortabel finde); aber selbst dies anzuzeigen kann man relativ performant implementieren: bind_columns nutzen und die Sachen gleich zusammenstellen zum Beispiel.
Aber, wie gesagt: Insgesamt gebe ich Dir im Wesentlichen Recht! Es gibt ja auch immer mehrere Wege, das Ziel zu erreichen.
Einige Hinweise zu Performance-Optimierung gibt es auch in einem alten Vortrag von mir.
Hallo Alvar
stimmt, wir spielen mit unseren privaten/halb privaten Webangeboten in einer anderen Liga - im real life habe ich es täglich mit einem permanenten Ausspielstrom von mehreren GBit zu tun - du fängst automatisch an, immer in solchen Dimensionen zu denken...
Es hat sich aber gezeigt, dass die Mechanismen, die die dicken Kisten zum Fliegen bringen, meist einfacher zu realisieren sind als das ganze Mainstream ORM / SQL Gefrickel.
Z.B. benutze ich liebend gerne Spread, wenn ich parallele (Klein) Systeme aufbaue - jeder Teil ist skalierbar, ich habe ein bis drei parallele memcachedb als Storage, die via spread versorgt werden (und somit sauber asynchron speichern), die Searchengine spricht Spread, damit kann ich mehrere Instanzen der CLucene aufsetzen und parallel abfragen (map/reduce). Transaktionen ersetze ich durch Prevayler+Semaphore. Meine Objekte wissen, welchem Server sie "gehören" und schicken dem Besitzer brav Nachrichten, wenn sie sich geändert haben oder auf einen anderen Server "umziehen" wollen - so ähnlich wie Terracotta, nur eben als Smalltalk/Perl-Combo. Wenn ein Objekt lange nicht gebraucht wurde, lagert es sich selbst aus und ersetzt sich durch einen minimalen Proxy - damit kann ich Terabytes an Objekten virtuell im RAM halten, ohne Verwaltungsaufwand.
Beim Entwickeln des Datenmodells baue ich damit nur noch Objekte und verschwende nicht einen einzigen Gedanken daran, ob sich das irgendwie oder sogar performant in SQL und Relationen abbilden läßt. Auch zyklische oder rekursive Datenstrukturen, die bei einem ORM-getriebenen Ansatz Gift fürs Modell sind, verlieren ihren Schrecken.
Dieses Setup ist erfahrungsgemäß Größenordnungen einfacher zu skalieren und zu warten als eine monolithische Perl/PHP/Java/SQL/ORM-Lösung - im Moment arbeite ich an einem Auto-skaling - wenn eine Ressource kanpp wird, startet der nächste Knoten eine neue Instanz...
Meines Erachtens ist das Hauptproblem die feste Verankerung in den Köpfen - im Klein- und Agentursektor gilt Web = LAMP, im Business heisst es Web = J2EE+Oracle. Andere Ansätze dürfen überhaupt nicht mehr gedacht, geschweige denn vorgeschlagen werden, obwohl sie der Problemstellung viel eher angemessen wären - aber das ist eine ganz andere Geschichte...
Hi Tonnere
Ich benutze seit Jahren jene Distribution, welche im Rufe steht, immer "gut abgehangene" Pakete im jeweils aktuellen Release zu haben. Ja, genau jene Distri, die sich im vergangenen Jahr (oder eigentlich wesentlich früher) den Bock mit OpenSSL geschossen hat. ;-)
Aber selbst diese liefert nur noch zurückportierte Security Fixes für 0.9.8c aus.
Was ich damit sagen will: Mir ist der Mechanismus des Zurückportierens von Code zur Fehlerbehebung durchaus bekannt. Nur ab einem gewissen Grad an Änderungen, wird die Komplexität so groß, dass man doch lieber auf eine etwas neuere Version zurückgreifen sollte. Von daher steht meine Frage noch, nach der Distri, welche aktuell OpenSSL 0.9.8a noch mit Security Fixes versorgt.
Gruß ZEITungsleser
Hallo, kannst du näher auf die Problematik von MyISAM eingehen, warum InnoDB besser ist, und das für Leute wie mich erklären die sonst nur kleinere Projekte umsetzen (ich übernehme alle MySQL Standard Einstellungen).
Danke.
Hallo Olaf,
Nun, was die Liga anbelangt, die definiert sich ja in erster Linie durch die Wichtigkeit des Angebots: wie wichtig ist es, dass es nicht ausfällt.
Die oft beschworenen exorbitant hohen Zugriffszahlen die ein System zum erliegen bringen sind in den seltensten Fällen tatsächlich so hoch, dass entsprechende Ausfälle durch Überlastung zwingend sind. Meist handelt es sich schlicht und ergreifend um schlechte Programmierung oder ungeschickte Konfiguration. Bei der Petitions-Webseite ist das nach allem was ich weiß auch nicht anders. Ein paar Tausend Benutzer pro Stunde sind ein Klacks – sofern die Applikation sauber geschrieben ist und man dies vorher eingeplant und getestet hat. Aber das waren ja die Anforderungen beim Petitions-System.
Dass man mit dem „Standard-Ansatz“ problemlos große Projekte skalieren kann zeigen beispielsweise heise online und XING. Beides wird mit Apache und Perl betrieben, und sogar MySQL ist mit dabei ... ;-)
Dass es auch anders geht, das ist keine Frage. Einfacher ist meist erst einmal das, was die Entwickler kennen – die einen nehmen ORM weil sie kein SQL können, ich bin mit SQL in den meisten Fällen schneller als die ORM-Leute und die damit erstellte Applikation ist sowieso performanter.
Spread sieht mir sehr interessant aus, werde ich mir bei Gelegenheit mal anschauen. Es ist ein ganz anderer Ansatz, hat aber garantiert auch seine spezifischen Probleme eben auf anderer Ebene. Wenn es jetzt nicht schon so spät wäre hätte ich ja vorgeschlagen, dass Du dazu einen Vortrag auf dem Perl-Workshop machen könntest ...
Zum Beispiel für die Kombination Apache, mod_perl und SQL-Datenbank spricht eben, dass diese Sachen – bei allen Problemen die man so hat – doch relativ weit ausgereift sind. Wenn man weiss was man tut, kann man damit mit relativ wenig Aufwand sehr komplexe und performante Anwendungen erstellen. Schon mit relativ wenig Wissen und einem anständigen RDBMS wie PostgreSQL (MySQL eher nicht) kann man Daten garantiert konsistent ablegen und es gibt viele Werkzeuge um mit den Daten zu hantieren -- und sei es nur die passende SQL-Shell.
Was die Wartbarkeit anbelangt, die hängt vor allem von der Art des Codes ab. Das SMF zum Beispiel mit seinen teilweise über 1000 Zeilen langen Unterfunktionen ist relativ schlecht wartbar (und das obwohl es im Vergleich zu manch anderem noch ein relativ guter PHP-Code ist) und unübersichtlich.
Wer sauber modularen Code schreibt, Module verwendet und die Vorteile von Namensräumen und Objektorientierung nutzt, sich an die Code-Komplexität-Regeln von Perl::Critic hält und so weiter kann problemlos sehr un-monolithischen Code schreiben, der sehr gut wartbar, effizient und skalierbar ist. Siehe auch den Vortrag hier, auch wenn es da nicht um Web-Sachen geht.
Der Hauptunterschied bei Deinem Ansatz ist ja die Ablage der Daten und was damit zusammen hängt. Dies ist tatsächlich der große Flaschenhals bei vielen Anwendungen, insbesondere wenn es um große Datenmengen geht. Einfach die Objekte abzulegen und sich nicht um die Details kümmern zu müssen erscheint mir auch wünschenswert – sofern das in der Praxis auch wirklich reibungslos klappt.
Lauch: OK, ich werde noch einen Artikel zum Thema „Warum man MyISAM meiden sollte“ schreiben. Aber das wird vermutlich noch ein paar Tage dauern.
Erstmal kommt einer zum Thema, wie man mit dem Apache und Perl (PHP, ...) gut skalierbare Anwendungen schreibt bzw. wie man ein Performance-Problem wie es hier vermutlich aufgetreten ist beheben kann.
Hallo Alvar,
langsam wird das gegenseitige "Recht geben" langweilig :-) Ich sehe schon,
wir haben in etwa die gleiche Wellenlänge.
Dass man mit LAMP ebenfalls performant sein kann, wurde schon oft unter
Beweis gestellt, dagegen will ich auch nichts sagen. Für alle Systeme gilt,
dass schon bei der Planung an eine Skalierung gedacht und vor Allem Tests
der Funktion und der Performance mit eingebunden werden müssen.
Das ist aber nicht der ganze Kuchen.
Vor die Aufgabe gestellt, "irgendwas im Web zu machen" lautet der
pawlowsche Reflex bei den meisten Entwicklern "LAMP!", bzw. bei
Entscheidern "J2EE". Andere Ansätze werden erst gar nicht in Erwägung
gezogen, Millionen Fliegen können schliesslich nicht irren.
Meines Erachtens liegt der Grund für diesen Reflex in der Tatsache, dass
Computer nur einige wenige Megabyte RAM haben und Prozesse nur 64 Kilobyte
große Speicherbereiche verwalten können. Daher müssen alle Daten in eine
Datenbank ausgelagert werden.
Damit kann man auch in den Daten suchen, schliesslich ist SQL extra
dafür gemacht.
Ende der Rückblende. Die obigen Aussagen waren 1990 wahr, sind es aber
heute nicht mehr. 1990 waren Platten von 4GB in Servern die Norm, das
haben kleinere Maschinen heute als RAM.
RDBMS sind sinnvoll, um Daten strukturiert abzulegen, sofern es sich um
tabellarische Daten handelt. Im Web hat man es aber meistens mit (rekursiven)
Baumstrukturen, also multidimensionalen Daten zu tun - die werden dann auf
zwei Ebenen plattgeklopft und in Tabellen gestopft um dann
- HTTP-Zustandslosigkeit sei Dank - eine Hundertstel Sekunde später wieder
aus den Tabellen ausgelesen und in die rekursive Baumstruktur überführt
zu werden.
Die SQL-Abfragemöglichkeiten sind den Web-Anforderungen nicht mehr angepasst.
Im Web ist Volltextsuche angebracht, die Daten sind in den seltensten Fällen
so strukturiert, dass SQL als Abfragesprache sinnvoll wäre.
(Wie viele "LIKE ?" haben wie alle schon geschrieben?)
In Zeiten billiger Platten ist eine Volltextsuche mit z.B. CLucene fast
immer schneller und Map/Reduce deutlich performanter als SQL.
Zurück zur Datenspeicherung:
Gerade die Perlianer sind sehr schnell mit Session::Store::MySQL und
Storable zur Hand, was meines Erachtens unnütz ist, wenn Perl green threads
unterstützen würde. Damit könnte ein einzelner Serverprozess mehrere tausend
parallele Abfragen abarbeiten und damit auf seine In-core-Daten zugreifen -
keine Session- oder Datenserialisierung mehr.
Der von Apache (1.x) aufgezwungene Ansatz "Ein Prozess pro Request" ist recht
schön, wenn man Systeme
voneinander isolieren möchte, die Kosten sind aber immens, da praktisch
bei jedem Request die kompletten Daten wieder von Null aufgebaut werden müssen.
Transaktionen folgen der gleichen Logik - schliesslich sorgen sie für einen
gewünschten "Alles oder Nichts"-Ansatz. Schade nur, dass das zustandslose
HTTP-Protokoll
so gar nicht zu Transaktionen passen will und ein geschlossenes/verlassenes
Browserfenster zu offenen Transaktionen auf dem Server führt, die andere
Transaktionen behindern. Auch hier ist ein Paradigmenwechsel angesagt,
man muss Transaktionen nicht um ihrer selber Willen einsetzen.
Bevor MySQL Transaktionen hatte, waren alle LAMPer fest überzeugt,
niemals Transaktionen zu brauchen...
Bei den allermeisten Applikationen gilt: es explodieren keine AKWs, es
fallen keine Flieger in Türme und es bleiben keine Herzschrittmacher
stehen, wenn ein Request unbeantwortet bleibt.
Daher entwerfe ich jetzt ein System, das m.E. für einen großen Prozentsatz
aller performanten Websysteme ausreichen sollte:
Loadbalancer, der Sessions immer auf den gleichen Knoten abbildet.
Mehrere Single-process Server, die mit green threads Sessions abbilden.
Spread als Kommunikationsprotokoll zur Verbindung mit
mehreren Searchengines (CLucene).
mehreren Key-Value-Storages, z.B. BDB, memcachedb etc.
Das Ganze hat den Vorteil, auf einer 1-CPU-Maschine genau so zu laufen wie in einem großen Cluster, ohne dass die Architektur angepasst werden müsste.
Uff, das ist ein langes Posting geworden, danke für die Geduld beim Lesen.
Tach,
das ist ja schön, dass ihr hier um die Wette superperformante Datenbankcluster in eure Wolkenkuckucksheime einbaut. Alvar hat es teilweise schon angesprochen: Das Petitionssystem muss weder die Datenflut von ebay noch die Zugriffszahlen von Google aushalten. 16.000 Datenbankzeilen hat jedes drittklassige Forum aufzuweisen, und von denen sind bestenfalls 8.000 in den letzten 3 Tagen zusammengekommen. Ich habe schon vor vielen Tagen unterzeichnet, da waren es auch schon tausende. Die Spitzenlast dürfte also kaum bei ein paar hundert Zugriffen pro Stunde gelegen haben. Das schafft ein stinknormaler Mietserver mit Standardinstallation locker.
Umso weniger ist es begreiflich, wie mit öffentlichen Mitteln umgegangen wird. Der IT-Dienstleister hat sich diesen Schrott sicher ordentlich bezahlen lassen, und niemand schaut mal rein, was da überhaupt gekauft worden ist? Diese Schlamperei bringt die Bürger nun um ihre demokratischen Grundrechte? Mich übermannt ein Gefühl unbändiger Wut und tiefer Resignation über soviel Unverfrorenheit und Dummheit.
Hallo Lutz,
ich muss dir Recht geben, der Thread hat sich recht weit von dem Ursprungsartikel entfernt; dass das Petitionssystem die aktuelle Last ohne Beeinträchtigung wegstecken müsste, wenn es als abgenommenes System an den Start geht, versteht sich von selbst.
Dass dieser Schrott so abgenommen wurde, wundert mich nicht, das hat mehrere Ursachen:
1. werden solche Projekte als Werk ausgeschrieben, heisst,der Auftraggeber weiss noch nicht was er braucht, hatte noch keine Beratung, muss aber genau spezifizieren, was er zu kaufen gedenkt.
2. er muss das billigste Angebot annehmen.
3. spielt Geld keine Rolex - der niedrigste Phantasiepreis sticht
4. gibt es einen festen Starttermin, der unter allen Umständen gehalten werden muss,
5. gibt bei den Auftraggebern einfach niemanden mit der Kompetenz, der das Produkt abnehmen könnte.
6. ist eine unabhängige Abnahme im Budget nicht drin
7. bleibt für eine Abnahme wegen Komplettlieferung kurz vor Starttermin keine Zeit.
Also kommt der "passt schon"-Stempel drunter und das Ding geht an den Start.
Dass die Software Stimmen unterschlägt, die Stimmabgabe massiv behindert und das Gesamtsystem damit obsolet macht, kommt den Auftraggebern meiner Ansicht nach gerade recht. Der Bundestag kann sich dann in zwei, drei Jahren auf den Punkt "Die Akzeptanz des Systems ging gegen NULL, es gibt offensichtlich keinen Bedarf an Petitionen" zurückziehen und das Ding abschalten - keine Arbeit mehr und man kann endlich wieder das Stimmvieh ohne Störungen melken.
Der Trend weg von gelebter Demokratie hin zum "Vereinten Polizeistaat Europa" ist seit Jahren spürbar, die Petitionswebsite ist nur eine Randerscheinung.
Hallo Olaf,
damit wir uns nicht die ganze Zeit nur Recht geben, möchte ich kurz bei ein paar Punkten widersprechen. Aber nur kurz, damit das ganze nicht ausartet und zudem ist das Teil hier nicht wirklich für übersichtliche Diskussionen geeignet ...
SQL hat einfach einige Vorteile: es ist sehr flexibel, es sind komplexe Abfragen möglich, man kann ohne großen Aufwand neue Abfragen reinbringen und so weiter. Wenn man nur mit Objekten arbeitet muss man da einiges mehr oder minder manuell implementieren. Wenn man nicht gerade mit MySQL arbeitet ;-) sind in SQL sehr flexible und performante Abfragen möglich.
Dass Perl-Entwickler schnell mit Session::Store::MySQL zur Hand wären (Du meinst Apache::Session?) wäre mir nicht bekannt – aber selbstverständlich nimmt man zum Beispiel Apache::Session für die Session-Verwaltung, wenn man eine solche braucht.
„Green Threads“ gibt es quasi auch, mit Coro und POE.
Mit Perlbal gibt es auch einen Reverse-Proxy/Load-Balancer, der auf den von Dir genannten Techniken basiert.
Aber in vielen Anwendungen sind ein-CPU-Anwendungen mit preemtivem Miltitasking eben nicht geeignet. Zum Beispiel kann ein kaputter Thread das ganze Teil lahmlegen – das will man natürlich nicht.
Transaktionen und HTTP: Transaktionen haben erstmal wenig mit dem zustandslosen HTTP zu tun; es geht nur darum, dass entweder alle Änderungen oder keine abgespeichert werden. Das braucht man zwingend unabhängig vom Protokoll.
Sessions bzw. Sessiondaten sind das kleinste Problem; ein Single-Prozess-Server löst nicht wirklich irgendwelche Probleme, letztendlich fügt er auch neue hinzu, zum Beispiel i.d.R. kurze Gültigkeitszeiten für Sessions. Und ob memcacheDB wirklich sinnvoller ist als eine relationale Datenbank, das ist dann wieder die große Frage. In manchen Fällen sicherlich; in vielen anderen nicht, da die Flexibilität fehlt.
Der einzige Vorteil in Deinem Vorschlag ist, dass er theoretisch einfacher skaliert. Praktisch skalieren auch normale Anwendungen gut, man kann problemlos ein paar weitere Webserver dazu packen; nur bei der Datenbank ist das ein wenig komplizierter, echte Multi-Master-Replikation ist nicht trivial. Und ob memcachedb wirklich besser skaliert und auch richtig stabil ist, das möchte ich mal bezweifeln. Eine relationale Datenbank ist natürlich deutlich flexibler und kann auf Datenbankebene Datenkonsistenz garantieren. Garantieren! Und das gehört genau da rein.
Auf jeden Fall ist es auch bei Deinem Vorschlag genauso wie überall: ein Entwickler der sich damit nicht auskennt und/oder entsprechende Fehler macht schafft es ruck-zuck, diese Kombination gegen die Wand zu fahren.
Soviel mal auf die Schnelle, um Dir auch mal zu widersprechen ;-)
Sieht es mir doch so aus, als würde die Hardware, mit welcher man nach den Problemem geworfen hat, nicht ganz bis zum Ende der Zeichnungsfrist ausreichen. Und dies, obwohl das Forum schon geschlossen wurde.
Das ist aber auch eine Gemeinheit, dass das Thema jetzt so kurz vor dem Ende noch einmal durch Bloghausen getrieben wird. ;-)
MfG ZEITungsleser
Ja, das sieht mir auch so aus. Schon heute Mittag hatte ich wieder Performance-Probleme bemerkt. Da sieht man wieder sehr gut: nur dickere Hardware hinstellen skaliert nicht (sofern es das war, was sie getan haben; aber vieles spricht dafür; hat jemand dazu eine offizielle Aussage?).
Hatte dir der User aus dem Heise Forum, jener der wusste, dass wohl doch innoDB anstatt MyISAM zum Einsatz kam, eigentlich per PM ein paar Infos zukommen lassen? Seine Aussagen hatten für mich irgendwie leichten Fnord Charakter. Aber wenn er ein wenig Licht in's Dunkel bringen konnte, kann man ja die Quelle evtl. noch einmal anzapfen.
MfG ZEITungsleser
Nein, der hat sich auch nach Nachfrage nicht gemeldet.
Derzeit dauern Requests zwischen 5 und knapp 30 Sekunden; auch bei statischen kleinen Bildern; das deutet stark auf eine schlechte Architektur der Server hin – da scheint mir ja auch der Hosting-Provider gefragt, die anständig zu beraten.
*SCNR*, aber ich habe eben in einem Forum die IT-Metapher des Monats bzgl. der Serverprobleme gelesen, und vor Lachen auf dem Boden gelegen:
"Also, das mit dem Server finde ich auch sehr mysteriös... Der kriecht da vor sich hin als müsste Inge Meysel Ottfried Fischer die Zugspitze hochtragen."Quelle
Gruß ZEITungsleser
Mein Problem bestand darin, dass ich über einen Zeitraum von mehr als einer Stunde (geschätzt etwa 15-17 Versuche) bei der Registrierung keinen Captcha angezeigt bekommen habe - weder grafisch noch per Audio.
Hallo Alvar,
was hältst du davon eine ePetition für eine erneute Ausschreibung des ePetitionssystem einzureichen? Ich würde auch direkt mit unterschreiben. Das aktuelle System ist ja echt grottig, das würde ich persönlich auch direkt auf SMF/MySQL schieben.
Ansonsten kann ich dein PHP-Bashing nicht verstehen, man kann auch mit PHP sauber arbeiten und schneller ist es wohl auch. CPAN ist zwar toll (solange man nicht in die CPAN hölle kommt, darfst mir gerne mal die zyklischen Abhängigkeiten diverser Module auf meiner Kiste auflösen), aber PHP hat "auch" sowas: PECL/PEAR.
Hallo Christoph,
wie ich gestern erfahren habe, gibt es eine solche Petition. Das dauert aber immer eine Weile, bis die freigeschaltet werden. Und ich finde sie in einigen Punkten ungeschickt formuliert.
Bezüglich PHP: Klar, man kann mit (fast) jeder Programmiersprache sauber arbeiten. PHP fehlen allerdings eine Reihe von wichtigen Sprach-Features, es ist für eine Skriptsprache recht unflexibel und mehrere tausend Funktionen im Haupt-Namensraum animieren auch nicht zur sauberen Struktur. Es stellt sich ja auch immer die Frage, welche Möglichkeiten zur sauberen Programmierung eine Sprache bietet.
CPAN-Abhängigkeiten lassen sich i.d.R. ganz gut auflösen, welche Probleme hast Du konkret?
PECL/PEAR kann man zwar entfernt mit dem CPAN vergleichen; allerdings bietet das CPAN ein vielfaches an Modulen, derzeit sind es 17636 Distributionen. Wenn man das mit den paar hundert in PEAR/PECL vergleicht ...
Nette Ideen zur Performanceverbesserung sind hier aufgezählt. Das Problem liegt definitiv im Backend und ist leider nicht nur an einer Stelle (DB) zu suchen. Es gibt da eine Hand voll Probleme. Schade, dass ich nicht ganz in der Server rein schauen kann, aber ein wenig kann man hier schon sehen....
http://www.kiutalk.de/2009/05/epetition-problemanalyse/
Ein weiterer Schwachpunkt des Systems ist es, dass es keine Sonderzeichen zulässt, die sehr wohl in Nachnamen vorkommen. So war meine Registrierung erst nach mehreren erfolglosen Versuchen durch die Umstellung der Schreibweise von ß auf ss möglich. Nach den erfolglosen Versuchen wurde mir bei einer Wiederholung der Registrierung angezeigt: "Die Registrierung von 2 Accounts von einem Computer ist nicht erlaubt. Starten sie ihren Browser neu!"(sinngemäßes Zitat)
@alva
Dann setz die Repositorygröße mal ins Verhältnis zum Alter der beiden Sprachen. I.A. bevorzuge ich PHP skripte einfach aus dem Grund weil die dann im Apache laufen und dort dann einen Cache benutzen können.
Das Problem war, das er bestimmte Pakete auf denen fast alle anderen Pakete basieren immer und immer wieder installiert. Wie in in einer Endlosschleife, aber frag mich jetzt nicht welche, ich bin froh, das ich seit Monaten kein perl -MCPAN -e shell eingeben musste.
Übrigens wurden bei der Petition die 50.000 geknackt, jetzt bin ich mal gespannt wo das Begehren versickert/abgeschmettert wird.
@Anonym
Perl Programme kannst du unter mod_perl laufen lassen, ebenfalls möglich ist es auch FastCGI oder andere Methoden zu nutzen.
Da Perl selber zu Bytecode kompiliert wird, passiert das nur einmalig beim Starten. Ein simples PHP mit mod_php wird aber Interpretiert. zwar ist der Interpreter in Apache integriert (genauso wie es der Fall bei mod_perl unter Apache ist) allerdiengs werdne die .php Dateien bei jedem aufruf immer wieder neu Interpretiert.
Bei Perl hat man aber im Gegensatz eine Persistente umgebung, was im gegensatz zu einem normalen mod_php zu einer höheren leistung führt.
Möchte PHP mit der Geschwindigkeit mithalten müsste man das Zend Framework nutzen oder erstmal einen PHP Opcode Cacher. Bei Perl kommt dies wie gesagt frei haus.
Der Bundestag hat eine neue Seite, vielleicht magst du ja drüber berichten, vor allem diese Möglichkeit mit Realplayer oder Flashplayer sich die Videos anzuschauen...
Ich habs mal ein klein bisschen unter die Lupe genommen. Fazit: ausreichend.
Es gibt deutliches Optimierungspotenzial.
www.kiutalk.de
Heute in einem Intranet irgendwo in Berlin:
Es wurde bei IT 4 ein neues Projekt aufgelegt:
ePetitionen-Neuentwicklung
=)