Vor einiger Zeit habe ich über die gravierenden Mängel des Online-Petitions-Systems vom Deutschen Bundestag berichtet. In der Zwischenzeit wurden zwar einige kleine kosmetische Reparaturen vorgenommen, das Grund-Problem der gammeligen Software besteht aber weiterhin. Unter der „hohen“ Last von rund 16000 Unterzeichnern einer Petition ist der Spaß jetzt zusammengebrochen. (Updates unten: Probleme halten an)
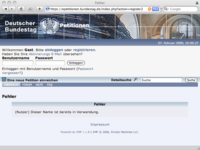
Seit einigen Tagen ist die Petition zum Bedingungslosen Grundeinkommen sehr beliebt und hat viele Unterzeichner erhalten, der Zähler steht bei über 16000. Nun zeigen sich die ganzen Mängel des unzureichenden Systems, wie einige Leser berichteten und ich verifizieren konnte: Durch einen Fehler ist es nicht mehr möglich, dass sich neue Nutzer registrieren und ohne Registrierung ist es auch nicht möglich Petitionen zu unterzeichnen. Dies äußert sich darin, dass nur eine Fehlermeldung erscheint:
Fehler
(Nutzer) Dieser Name ist bereits in Verwendung.
Dies dürfte an einem Datenbank-Fehler liegen und eine Folge der Wahl der technischen Basis sein – die den grundlegenden Anforderungen des Bundesamts für Sicherheit in der Informationstechnik (BSI) widerspricht. Ein paar technische Hintergründe dazu weiter unten.
Das ist aber nicht alles: die PHP/MySQL-Software ist auch an anderer Stelle bei rund 16000 Unterzeichnern einer Petition überfordert, die Anzeige der Unterzeichner wurde daher generell auf 100 begrenzt. Das sieht wie eine schnell eingebaute Notmaßnahme aus, um die Last des Systems zu begrenzen. Denn laut diversen Berichten wurde das Petitionssystem zuvor immer langsamer. Auch das ist ein Zeichen für schlechten Code.
Die Beschwerden im Forum häufen sich, zumal die Zeichnungsfrist für die Grundeinkommens-Petition am 10. Februar abläuft. So fragt der Nutzer Thomas Köppel:
Tja, wie es aussieht ist das System auf dem die Petitionssoftware (Datenbank) aufgesetzt ist, an seine Grenzen gestoßen.
Es bedarf wohl einer besseren Infrastruktur, für das handling des großen Datenaufkommens, ich frage mich was passiert wenn über 1 Millionen Menschen gleichzeitig Zugriff auf das System nehmen.
Viele Grüße
T.K.
Eine Million gleichzeitiger Zugriffe würde zwar fast jedes System zum erliegen bringen; aber insgesamt bei einer Million Unterzeichnern (bzw. Datenbankeinträgen) hat ein anständiges Datenbanksystem keine Probleme. Schließlich sind Datenbanken dafür da, große Datenmengen effizient zu verwalten.
Und Nutzer16941 schreibt:
Das ist leider ein Armutszeugnis für unsere Demokratie (und damit für uns das Volk), wenn unsere Regierung davon ausgeht eine kleines(?) System reicht aus. Denn scheinbar hat es das ja seit Jahren.
Dazu ist anzumerken, dass die Anforderungen an das neue System u.a. waren, dass es im Peak 50000 Nutzer sowie Petitionen mit beliebig vielen Unterzeichnern aushalten muss. Hier zeigt sich wieder, dass das neue System wie beschrieben eben nicht den Anforderungen entspricht.
Denn all das erinnert an das alte Petitions-System, das noch vom schottischen Parlament erstellt wurde. Nun wollte man alles besser machen, aber es wurde nur ein tiefer Griff ins Klo in die Problemkiste: Eine Bundestagsverwaltung, die technische Angebote nicht lesen und verstehen kann (schließlich haben die dortigen Mitarbeiter normalerweise anderes zu tun) und sich daher auf die Behauptungen in den Angeboten verlassen muss, ein Ausschreibungsrecht, dass den günstigsten Anbieter verlangt und eine Firma, die alles mögliche behauptet aber nicht viel einhält – all das zusammen sind meines Erachtens die Hauptgründe für das Dilemma. Den Bundestag sehe ich dabei eher als Opfer.
Aus mehreren Quellen weiss ich, dass derzeit eine Studie zur Online-Petitions-Plattform für das Büro Technikfolgenabschätzung des Bundestages erstellt wird. Die Plattform wird vor Fertigstellung der Studie wohl kaum grundlegend überarbeitet werden – und es ist zu hoffen, dass sie danach komplett weggeworfen und ein ganz neues, sauberes System erstellt wird. Dem Petitionswesen wäre das zu wünschen.
Und woran liegen die Probleme aus technischer Sicht?
Das Problem, dass niemand mehr registriert werden kann, liegt vermutlich an einem Datenbank-Problem, das unter Last auftreten kann. Dazu muss man wissen, dass die Nutzer ihren Nutzernamen nicht frei wählen können, sondern einen Namen „Nutzer12345“ mit fortlaufender Nummer zugewiesen bekommen. Die Petitions-Software basiert auf dem „Simple Machines Forum“, das als Datenbank-Backend MySQL mit MyISAM-Tabellen verwendet – was keine Transaktionen und Datensicherheit unterstützt und bei mehreren gleichzeitigen Zugriffen ohne besondere Maßnahmen sehr langsam wird und schon mal den einen oder anderen Fehler erzeugt. Aber auch wenn Transaktionen unterstützt werden können können ähnliche Probleme auftreten, beispielsweise zwei gleichzeitige nicht synchronisierte Zugriffe (zum Beispiel durch das fehlende Sperren einzelner Datensätze) und der Zähler für die Erstellung der Nutzernamen ist durcheinander gekommen. Dies nennt man Race Condition (Wettlaufsituation), zwei oder mehr Zugriffe rennen quasi um die Wette und greifen gleichzeitig auf eine Ressource zu, die nur einmal vorhanden ist.
Dumm gelaufen – bei professioneller Software darf sowas nicht passieren. Darum verlangt das BSI ja auch entsprechende Mechanismen und eine ACID-Konforme Datenbank bzw. Software, die diese Funktionen auch nutzt. Aber der Dienstleister hat sich nicht daran gehalten. (mehr zur Petitions-Software ...)
Die langsamen Antwortzeiten bei vielen Unterzeichnern hängen möglicherweise auch (aber nicht nur) mit MySQL und MyISAM zusammen, ein übliches Szenario ist: die Queries (Datenbank-Abfragen) dauern bei vielen Unterzeichnern (also vielen Daten) länger, sperren aber schon beim Lesen die ganze Tabelle für Schreibzugriffe. Schreibzugriffe müssen warten und wenn diese dran sind, müssen die Lesezugriffe warten. So schaukelt sich das ganze unter Last bis zur Unbenutzbarkeit hoch und schon bei relativ niedrigen Nutzerzahlen kann alles zusammenbrechen. Eine andere Möglichkeit ist, dass durch mehrere gleichzeitige lang laufende Datenbankabfragen die Performance in den Keller geht, dadurch mehr Abfragen gestartet werden und irgendwann der Speicher voll ist.
Zudem wurden in letzter Zeit wieder diverse gravierende Sicherheitslücken im verwendeten Simple Machines Forum bekannt. Auch das sorgt nicht gerade für Vertrauen in die Petitions-Plattform. Ebensowenig wie gelöschte Forums-Einträge und gesperrte Diskussionen. Beispielsweise ein gut implementiertes Bewertungssystem könnte das Löschen von Einträgen nahezu unnötig machen.
Die Probleme der Software sind meines erachtens eine große Schande für die Firma araneaNET GmbH, die groß damit wirbt BSI-Zertifiziert zu sein, aber dann MySQL und auch noch Software ohne Transaktionen verwendet, was eben nicht den BSI-Anforderungen entspricht und einer der Gründe der schwerwiegenden Probleme sein dürfte. Auch eine simple Änderung von MyISAM zu InnoDb ändert an der grundsätzlichen Problematik des Simple Machine Forums nichts. Da sieht man mal wieder: solche Zertifikate sind oft nur Schall und Rauch und sagen nur aus, dass da jemand ein wenig Geld in Marketing und vielleicht theoretische Fortbildung steckt.
[Nachtrag, 16:17:]
Ein weiterer Forums-Beitrag von Roswitha61 deutet auf mehr Probleme hin:
Bei mir erscheint "nur eine Mitzeichnung erlaubt". Ich habe mich aber gerade erst registriert und folglich noch gar nicht unterzeichnet.
Was ist das?
Sollte dies echt sein, könnte es sein, dass es noch weitere und massive Datenbank-Probleme gibt.
Die eingangs geschilderte Fehlermeldung erschien bei meinen Tests nun nicht mehr, aber es kommt bei einer Registrierung auch keine Bestätigungsseite und die Bestätigungs-E-Mail habe ich auch nicht erhalten.
[Nachtrag, 8. Februar, 12:15:]
In der Zwischenzeit scheint die Registrierung tatsächlich wieder zu funktionieren. Ich hatte es gestern Nachmittag und Abend mehrfach probiert, wurde aber nach Absenden des Registrierungsformulars ohne weiteren Kommentar oder Fehlermeldung auf die Startseite umgeleitet. Auch eine Bestätigungs-Mail ist nie eingetroffen. Dies lag daran, dass ich vergessen hatte den „Ich bin einverstanden“ auszuwählen. Es wird keine entsprechende Fehlermeldung ausgegeben, sondern der Nutzer wird dann nur auf die Startseite umgeleitet – auch das ist nicht sehr benutzerfreundlich. Einträge im Forum zeigen, dass dies nicht nur mir so passiert ist, die „Ich bin einverstanden“ Checkbox ist nicht sonderlich gut positioniert. Und es häufen sich auch die allgemeinen Beschwerden über die schlechte Benutzerführung.
Zudem konnte man bisher eine Unterzeichnung wiederrufen; da nur noch 100 Unterzeichner angezeigt werden und darunter nicht die neusten sind, findet man sich selbst aber nicht mehr in der Unterzeichnerliste und kann damit eine Unterzeichnung auch nicht rückgängig machen ...
Das obige Problem, dass das Petitionssystem behauptet der Nutzer hätte schon unterzeichnet obwohl dieser da anderer Ansicht ist, tritt auch bei weiteren Nutzern auf. Ob diese nur zweimal auf den Unterzeichnen-Button geklickt haben oder es tatsächlich ein Fehler ist kann ich aber nicht sagen. Ordentliche Software würde dies aber entsprechend abfangen ...
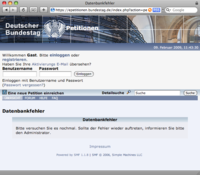
[Nachtrag 9. Februar, 15:32]
Heute reagiert die Petitions-Webseite wieder extrem langsam, manchmal treten auch Datenbank-Fehler auf (siehe Screenshot rechts). Der Zugriff auf eine Seite kann schon mal mehrere Minuten dauern, ganz abbrechen oder mit einer solchen Fehlermeldung enden.
Selbst das Laden eines statischen Bildes dauert schon mal mehrere Sekunden bis Minuten oder wird ganz abgebrochen. Dies deutet auf tiefergehende Probleme hin (Überlastung aufgrund sich gegenseitig blockierender Datenbankzugriffe und dadurch zu vieler Apache-Prozesse) – was ich gleich mal zum Anlass nehme, um in einem eigenen Artikel Tipps zum Umgehen dieser Probleme zu schreiben.
Bereits heute Vormittag wurde aufgrund der Probleme die Zeichnungsfrist für die Petition „Bedingungsloses Grundeinkommen“ um eine Woche verlängert. Das Forum wird aber morgen geschlossen – wahrscheinlich wird es den Moderatoren einfach zu viel Arbeit. Tja, mit einem selbstregulierenden System mittels eines flexiblen Bewertungssystems hätten sie kaum Arbeit, da die Nutzer die Trolle gleich selbst entsorgen könnten.
[Nachtrag 10. Februar, 16:10]
Die Probleme mit der Performance bestehen weiterhin: Lange Wartezeiten, teilweise kommt auch der gleiche Datenbankfehler wie im Screenshot eins weiter oben, und manchmal schlägt auch der Timeout vom Browser zu. Die große Frage ist, ob überhaupt Maßnahmen ergriffen werden, die Probleme zu beseitigen.
[11. Februar, 0:25]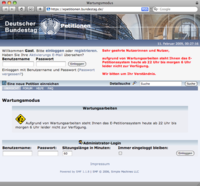
Nun ist alles im „Wartungsmodus“ und außer Betrieb. Vielleicht wird nun alles auf besser ausgestattete Hardware umgezogen. Nach dem Motto: Versuchen wir mal unzureichende Software mit dickerer Hardware zu erschlagen.
Unteressanterweise änderte sich die Darstellung der Fehlermeldung innerhalb weniger Minuten, anfangs war der rote Text oben noch schwarz und nicht fett ...
[12. Februar]
Tatsächlich, die Last-Probleme scheinen zumindest vorerst behoben zu sein.
[17. Februar]
Der Server ist wieder zusammengebrochen, Datenbankfeher inklusive ...
[4. Mai]
Und bei der neuen Online-Petition gegen Internet-Sperren wird der Server wieder langsam ... Sehr langsam ...
]]>

